
При больших объемах данных программы имеют свойство работать очень продолжительное время. А пользователи, в свою очередь, хотят, чтобы это время было минимальным.
Если оптимизация запросов и алгоритмов уже не помогает, можно попробовать распараллелить обработку. Задача довольно редкая, актуальных разработок не сохранилось, поэтому не буду здесь приводить примеров кода, а просто вкратце расскажу про два способа. Возможно через какое-то добавлю код.
Метка: ABAP
Отладка фоновых задач
Часто, возникает потребность трассировки тех или иных фоновых процессов. Одно дело, если мы сможем сделать все это в системе разработки.
1. Делаем бесконечный цикл с выходом по условию.
2. Запускаем программу
3. Переходим в sm50, выбираем наш процесс
4. В меню выбираем Администрирование->Программа->Отладка
5. Открывается экран отладки, в нем мы меняем значение нашей переменной, чтобы выйти из бесконечного цикла и начинаем отладку.
Однако, бывают случаи когда этот метод не работает. Т.к., например, в продуктивной системе нельзя менять значения переменных в отладчике(Можно конечно делать временную задержку вместо бесконечного цикла). Да и нести такой код в продуктив как-то не очень красиво.
В таких случаях можно воспользоваться ФМом k_plan_wait_for_debugging.
Ошибка при экспорте данных в XLSX из ALV
При выгрузке данных стандартным функционалом ALV возникла ошибка Удаленный компонент: часть/xi/sharedStrings.xml

Оказывается, проблема была в спецсимволах в строках для вывода. В нашем случае, ALV не понравилась решетка #. Решение на май 2018 только одно - удалить спецсимволы или попытаться выгрузить в другой формат.
Читаем Инфо-Типы по новому
Существует два буфера для ИТ:
Буфер PS - используется, когда для обновления основных данных вызывается функциональный модуль 'HR_INFOTYPE_OPERATION'. При чтении основных данных с помощью функционального модуля 'HR_READ_INFOTYPE'.
Буфер PRELP - также называется буфером PNP. Предназначен для работы с огромными объемами данных. В программах PNP не следует вызывать функции, считывающие инфо-типы с буфером PS или другим буфером. Потому что это вызывает задержку в чтении.
При чтении данным классом используется тот же буфер, который использует ЛБД.
|
1 2 |
cl_hrpy_infty_reader_factory=>initialize_factory( imp_mode = cl_hrpy_infty_reader_factory=>mode_pnpce ). mo_reader = cl_hrpy_infty_reader_factory=>get_read_infotype( ). |
Получение данных из ALV стандартных отчетов
Получим данные из отчета rm07mlbd
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
DATA: lr_data TYPE REF TO data. FIELD-SYMBOLS: <lt_data> TYPE table. "Инициация cl_salv_bs_runtime_info=>set( EXPORTING display = abap_false metadata = abap_false data = abap_true ). "Вызов отчета rm07mlbd, для примера SUBMIT rm07mlbd WITH matnr = p_matnr " Номер материала WITH werks = p_werks " Завод WITH lgort = p_lgort " Склад WITH datum = p_date "дата WITH xsum = abap_false WITH pa_sumfl = abap_true WITH pa_sflva = '/ZMB5B_KR' AND RETURN. TRY. "Получаем таблицу значений cl_salv_bs_runtime_info=>get_data_ref( IMPORTING r_data = lr_data ). ASSIGN lr_data->* TO <lt_data>. CATCH cx_salv_bs_sc_runtime_info. MESSAGE 'Ошибка чтения данных отчета mb5b'(003) TYPE 'E'. ENDTRY. cl_salv_bs_runtime_info=>clear_all( ). |
Вывод нескольких ALV в одном контейнере
Периодически возникает потребность вывести несколько таблиц на одном экране
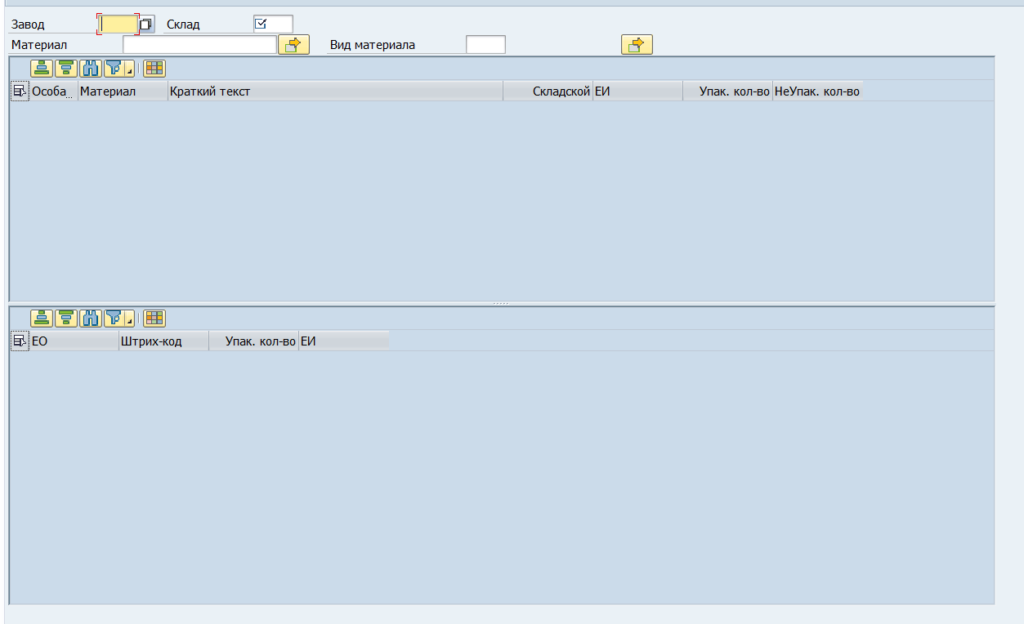
Все это можно сделать в одном контейнере, при этом обновлять таблицы можно как вместе так и отдельно. Также у каждой таблицы будет своя панель кнопок и заголовок.
Создадим небольшой пример. В верхнюю таблицу выводим материал и по двойному щелчку информация по нему отображается в нижнем окне.