
Немного сумбурных мыслей.
Информация для разработчиков, которые ранее не работали с модулем HR и не очень понимают, зачем при разработке в данном модуле использовать ЛБД или ФМ для выборки данных вместо селектов. Как всегда более подробно в курсах. В данном случае это HR350. Не претендую на идеальное и полное изложение материала.
Инфо-тип - это информационная единица, используемая для ведения основных данных, связанных с системами управления персоналом SAP. Проще говоря, это некий набор данных по определенной теме, описывающий объект HR. При этом объектом HR может быть как табельный номер (P) так и, например, организационная единица (O) или любой из других объектов.
Инфо-типы, относящиеся к управлению персоналом PA мы можем смотреть и редактировать в транзакциях PA20\PA30.
Для инфо-типов организационного менеджмента OM существует транзакция PP01.
Для разработчика данные из этих ИТ могут быть доступны в таблицах PAXXXX для инфо-типов администрирования персонала и таблицах HRPXXXX для инфо-типов OM. В свою очередь, Инфо-типы ОМ разделяются на ИТ с табличной и без табличной части.
Может быть не совсем ясно, почему же мы не можем просто использовать SELECT.
Причины использования ФМ и ЛБД для выборок
Во-первых, проверка полномочий, дело в том, что полномочия в HR это очень сложная и запутанная тема. У людей может быть очень много ограничений и вручную все эти проверки делать очень трудозатратно, да и самому все учесть практически не реально. В HCM проверка полномочий обязательна.
Во-вторых, не все, что мы видим на экране, лежит в таблицах PAXXXX или HRPXXX. Например, такой ИТ как 0008 "Основные выплаты" может содержать данные в таблице PA0008, а может и не содержать. Данные же надо собирать методом косвенной оценки.
В третьих, использование ЛБД облегчает написание кода в разы. Создание селекционного экрана, средств поиска, выборка данных из ИТ - все это ЛБД умеет из "коробки".
Пример кода. Рисуем селекционный экран, и выбираем данные ИТ 0001, 0002, 0006. Согласно заполнению экрана.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
TABLES pernr. " СЭ NODES peras. " Самый используемый узел в Z отчетах INFOTYPES: 0002, 0001, 0295, " Распоряжения по исполнительным документам (СНГ) 0296, " Исполнительные документы (СНГ) START-OF-SELECTION. GET peras. "Получается цикл по табельным в Этом событии " данные, удовлетворяющие выборке, лежат в таблицах "p0001, p0002, p0295, p0296 "Мы можем менять выборку на дату END-OF-SELECTION. |
Получившийся экран:
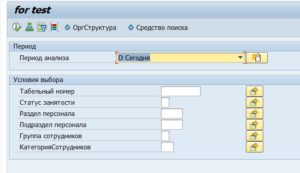
В четвертых, простота поддержки. Относительно малый объем обрабатываемых данных позволяет не думать об оптимизации, которую дает нам прямой select. Таблицы на несколько миллионов строк, это как правило не про HR, поэтому наш супер оптимизированный запрос (а таким он не будет, я видел ваш код))), видимого для пользователя прироста скорости, скорее всего, не даст. А вот поддерживать и дорабатывать все это хозяйство, исходя из вышесказанного, довольно проблематично.
Об удобстве последующей поддержки можно говорить долго. Всегда для разработчика возникает большой соблазн собрать все данные одним "метким" селектом. Но специфика данных в HR потребует для этого слишком сложные запросы, которые в дальнейшем потребуют очень много времени на понимание. Или мы вернемся к тому, что будем считывать ИТ отдельно во внутренние таблицы и потом работать с ними также, как и при выборке через стандартные средства.
Сравним на примере select-а который работает кое как с полученим данных при помощи ЛБД.
Сразу говорю, в код сильно вникать не надо. Изначально задача такая: Мы берем из ИТ 0295 записи только с соответствием в ИТ0296, а также выводим данные ИТ 0001 и данные ИТ 0002 инфо-типов.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
select PA0001~BUKRS && ' ' && T001~BUTXT as company, pa0296~pernr, PA0002~NACHN && ' ' && PA0002~VORNA && ' ' && PA0002~MIDNM as fio, pa0295~BEGDA, pa0295~ENDDA, pa0295~ORDCD, " Тип распоряжения по ИЛ pa0296~GRNUM, " Внутренний № pa0296~LIFNR, " Получатель, код LFA1~NAME1 && LFA1~NAME2 && LFA1~NAME3 && LFA1~NAME4 as lifnr_name, " Получатель, наименование pa0296~GCATE, " Категория ИЛ, код T7RUGX~GCATX, " Категория ИЛ, наименование PA0295~DEDUC, " Размер удержания по распоряжению (в % или суммой) PA0295~DEDUT, " ЕИ удержания pa0296~GCASE, " Номер ИЛ pa0296~ZZ_VIDOSP, " Орган выдачи ИЛ, код LFA2~NAME1 && LFA2~NAME2 && LFA2~NAME3 && LFA2~NAME4 as ZZ_VIDOSP_name, " Орган выдачи ИЛ, наименование LFA2~ORT01 && ', ' && LFA2~STRAS as ZZ_VIDOSP_address " Адрес РОСП into table @data(tab) from pa0296 inner join PA0295 on PA0295~PERNR = PA0296~PERNR and PA0295~GRNUM = PA0296~GRNUM inner join PA0001 on PA0001~PERNR = PA0296~PERNR and PA0001~ENDDA = '99991231' inner join T001 on T001~BUKRS = PA0001~BUKRS inner join PA0002 on PA0002~PERNR = PA0296~PERNR and PA0002~ENDDA = '99991231' left join LFA1 as LFA1 on LFA1~LIFNR = PA0296~LIFNR left join T7RUGX on T7RUGX~GCATE = pa0296~GCATE and T7RUGX~SPRSL = 'R' and T7RUGX~LAND = 'RU' left join LFA1 as LFA2 on LFA2~LIFNR = pa0296~ZZ_VIDOSP where pa0296~pernr = @employee_id and pa0295~ORDCD in @lr_ORDCD. " фильтр по типу распоряжения |
В варианте с ЛБД у нас в событии get peras все данные ИТ уже выбраны во внутренние таблицы PXXXX. Осталось только дополнить строки таблицы PA0295 остальными. Это выглядит вот так:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
LOOP AT p0295 ASSIGNING FIELD-SYMBOL(<ls_p0295>) WHERE ordcd IN lr_ordcd AND begda <= mv_endda AND endda >= mv_begda. APPEND INITIAL LINE lt_result ASSIGNING FIELD-SYMBOL(<ls_result>). READ TABLE p0296 ASSIGNING FIELD-SYMBOL(<ls_p0296>) WITH KEY grnum = <ls_p0295>-grnum. CHECK sy-subrc = 0. CHECK <ls_p0296>-zz_vidosp IN mr_vidosp. "Макросы ЛБД, которые берут последнюю запись ИТ нужного подтипа в периоде "Если мне надо взять самую последнюю запись ИТ, как в примере кода с запросом, "Достаточно просто поменять здесь не вникая в остальной код "Поддерживать это гораздо проще rp_provide_from_last p0002 space <ls_p0295>-begda <ls_p0295>-begda. rp_provide_from_last p0001 space <ls_p0295>-begda <ls_p0295>-begda. <ls_result>-company = get_company_name( EXPORTING iv_bukrs = p0001-bukrs ). <ls_result>-employee_id = p0002-pernr. <ls_result>-employee_fio = |{ p0002-nachn } { p0002-vorna } { p0002-midnm }|. <ls_result>-begin_date = <ls_p0295>-begda. <ls_result>-end_date = <ls_p0295>-endda. <ls_result>-grnum = <ls_p0295>-grnum. <ls_result>-sum_debt = get_sum_debt( EXPORTING it_p0295 = p0295[] ir_dolg = lr_dolg iv_grnum = <ls_p0295>-grnum ). <ls_result>-sum_retention_by_order = <ls_p0295>-deduc. " Сумма удержания по распоряжению <ls_result>-creditor_id = <ls_p0296>-lifnr. " Получатель <ls_result>-creditor_name = get_lfa1_name1( EXPORTING iv_lifnr = <ls_p0296>-lifnr ). " Наименование получателя <ls_result>-category_id = <ls_p0296>-gcate. " Категория ИЛ <ls_result>-category_name = get_category( EXPORTING iv_gcate = <ls_p0296>-gcate ). " Наименование категории ИЛ <ls_result>-order_id = <ls_p0296>-gcase. <ls_result>-agency_id = <ls_p0296>-zz_vidosp. " Орган, выдавший ИЛ <ls_result>-agency_name = get_lfa1_name1( EXPORTING iv_lifnr = <ls_p0296>-zz_vidosp ). <ls_result>-agency_address = get_lfa1_ort01( EXPORTING iv_lifnr = <ls_p0296>-zz_vidosp ). " ENDLOOP. |
Да, дополнительно мы используем некоторые методы для справочников, но это не критично для понимания удобства.
Если же мы работаем со вставкой и изменением данных, то тут и разговоров нет, ведение только через Стандартные ФМ и классы.
Краткий итог: если видим select к ИТ - удаляем его и переписываем так, как надо это делать в HR.